pca_vs_classf
Feature curves showing the replacement of PCA by a classifier
PRTools should be in the path. See http://37steps.com/prtools for more. Download m-file from Download the m-file from here
Three classifiers are considered:
- Fisher
- 95% PCA followed by Fisher
- Fisher followed by Fisher.
The experiment is based on an 8-class dataset with feature sizes up to 200. Feature curves, based on 10 repeats of randomly chosen training sets, are computed up to 200 features. Three sets of curves are created: for 10, 100 and 1000 training objects per class.
Contents
Initialization
Define the classifiers and the parameters of the experiment
delfigs prwaitbar off repeats = 10; randreset; % take of reproducability classf1 = setname(fisherc,'Fisher'); classf2 = setname(pcam(0.95)*fisherc,'PCA95 + Fisher'); classf3 = setname(fisherc*fisherc,'Fisher + Fisher'); classfiers = {classf1,classf2,classf3}; trainingset= genmdat('gendatm',200,1000*ones(1,8)); testset = genmdat('gendatm',200,1000*ones(1,8)); featsizes = [2 3 5 7 10 14 20 30 50 70 100 140 200];
small sample size
A training set of 10 objects per class is used. This is smaller than almost all feature sizes that are considered.
figure; trainsize = 0.01; tset = gendat(trainingset,trainsize); featcurves = clevalf(tset,classfiers,featsizes,[],repeats,testset); plote(featcurves,'noapperror'); title('Small trainingset: 10 objects per class'); legend Location southeast
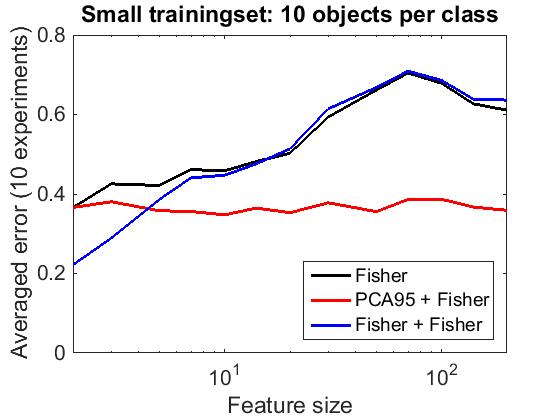
Feature reduction by PCA is for small sample sizes globally good. Supervised training of two routines like in Fisher preceded by Fisher is only useful for small feature sizes.
intermediate sample size
A training set of 100 objects per class is used. The total size (800) is thereby larger than the highest feature size considered (200).
figure; trainsize = 0.1; tset = gendat(trainingset,trainsize); featcurves = clevalf(tset,classfiers,featsizes,[],repeats,testset); plote(featcurves,'noapperror'); title('Intermediate trainingset: 100 objects per class'); legend Location southeast
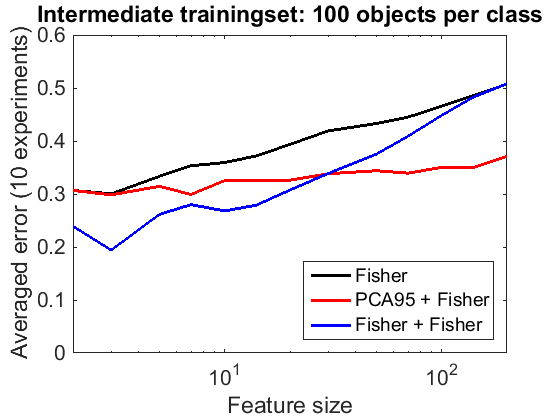
Feature reduction by PCA is for intermediate sample sizes globally good, but is for small feature sizes outperformed by a preprocessing by Fisher. In these cases the training set is sufficiently large to train a second routine on the outputs of a first one.
large sample size
A training set of 1000 objects per class is used. The total size (8000) is thereby much larger than the highest feature size considered (200).
figure; featcurves = clevalf(trainingset,classfiers,featsizes,[],repeats,testset); plote(featcurves,'noapperror'); title('Large trainingset: 1000 objects per class'); legend Location southeast
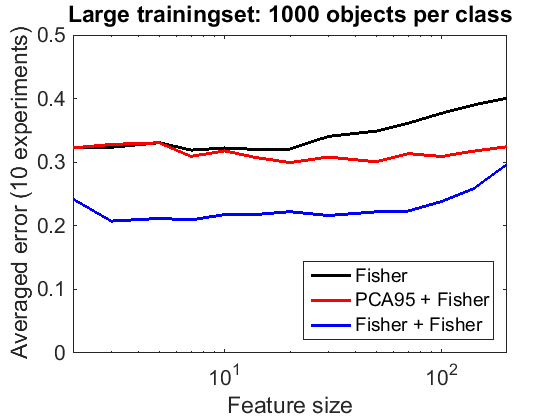
For large training sets, feature reduction by PCA is useful for larger feature sizes. However, for the considered feature sizes it is everywhere outperformed by a preprocessing by Fisher. Apparently, the training set is sufficiently large to train a second routine on the outputs of a first one.